save_format
"save"で作成されるファイルの形式
概要
本文書の目的はデータをScilabでデータ保存に使用されるHDF5形式について規定することです.
この形式はSOD (Scilab Open Data) と呼ばれます.
SODの最初の公開リリースは Scilab 5.4.0で行われました.
動機
相互運用性は近代的なソフトウエアの主要な特性の一つです. この特性をより改善するため, このSEPにおいて HDF5 形式の標準定義 が提案されました.
Scilab 5.2.0以降, エキスポート/インポート機能が開発され, データ交換用に管理されています. これは, 既にデータを保存および交換するためのXcosの基本要素の一つです.
サポートされるデータ型
全てのScilabデータ型がサポートされます. 例えば:
| 名前 | Scilabにおける例 |
| double | |
| string | |
| boolean | |
| integer | |
| polynomial | |
| sparse | sp=sparse([1,2;4,5;3,10],[1,2,3]) |
| boolean sparse | dense=[%F, %F, %T, %F, %F %T, %F, %F, %F, %F %F, %F, %F, %F, %F %F, %F, %F, %F, %T]; sp=sparse(dense) |
| list | l = list(1,["a" "b"]) |
| tlist | t = tlist(["listtype","field1","field2"], [], []); |
| mlist | M=mlist(['V','name','value'],['a','b';'c' 'd'],[1 2; 3 4]); |
複数の"types"は,tlist または mlist に基づいています. これは, rational, state-space, cell および structの場合です. これらは透過的に保存されます.
voidおよび undefinedは, リスト管理において特別な場合を管理するために作成された特殊な要素です. これらはこの文書にて後述します.
HDF5ファイルの構造
Scilab HDF5 アーキテクチャは非常に簡単です.
General各Scilab変数について, ルート位置におけるデータセットが宣言されます. データセットの名前はScilab変数の名前です.
例, 以下のコード:
emptyuint32matrix = uint32([]); uint32scalar = uint32(1); uint32rowvector = uint32([1 4 7]); uint32colvector = uint32([1;4;7]); uint32matrix = uint32([1 4 7;9 6 3]); save("uint32.sod","emptyuint32matrix","uint32scalar","uint32rowvector","uint32colvector","uint32matrix");
produces:

各ルートデータセットはSCILAB_Classと呼ばれる
属性を有します.この属性は, HDF5ファイルに保持される変数の型を定義します.
変数がプリミティブ型で関連する複合値がない場合, データは直接データセットに保存されます. それ以外の場合, データセットは実際のデータへのリファレンスを有します.
各 SOD ファイルは2つの固有の変数を有します:
SCILAB_scilab_version? SODファイルに保存する際に使用された Scilabのバージョンを記述します.例えば, Scilab 5.4.0の場合, このデータは以下となります:
SCILAB_scilab_version = scilab-5.4.0
SCILAB_sod_version ? SODファイルに保存する際に使用された SOD規約のバージョンを記述します.
例えば, Scilab 5.4.0の場合, このデータは以下となります:
SCILAB_sod_version = 2
データがデータセット内で直線的に保存される型
| Scilab 型 | HDF5 Scilab 型属性 | HDF5 属性 | HDF データ型マッピング |
string |
SCILAB_Class = string |
String | |
boolean |
SCILAB_Class = boolean |
32ビット 整数 | |
integer |
SCILAB_Class = integer |
SCILAB_precision = {8, 16, 32, u8, u16, u32} |
8 = 8ビット文字 16 = 16ビット整数 32 = 32ビット整数 u8 = 8ビット符号無し文字 u16 = 16ビット符号無し整数 u32 = 32ビット符号無し整数 |
これらの型について, Scilabにおける場合と同様に, データは1次元配列に保存されます.データは列方向に保存されます.
行列, ベクトルまたはスカラーを再構築するために, 2つの属性が列と行の数を指定します.
5.4.0リリースおよび SOD v2以降,
SCILAB_cols およびSCILAB_rows は
double, 整数, 多項式および文字列の行列ではもはや使用されなくなりました.
SOD はネーティブな多次元HDF5機能を使用します.
例
宣言の保存: int32([1 -4 7;-9 6 -3]) は,hdfviewで以下のように表示されます:
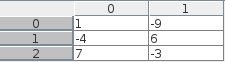
metadataは以下のようになります:
int32matrix (800, 2)
32-bit integer, 3 x 2 => the size of the variable
Number of attributes = 2
SCILAB_Class = integer
SCILAB_precision = 32
 | スカラー値は1行1列の行列に保存されます. |
空の変数 ([]) はtrueに設定された属性SCILAB_emptyを有します.
データが専用のグループに保存される型
Scilabデータ型の多くはグループで保存されます. これにより,値の分離を明確にでき,アクセスも容易になります.
グループは"#"で括られた変数から命名されます.例えば, matrixofdoubleと呼ばれるdoubleの行列の場合, ルートデータセットの名前は matrixofdoubleとなり, 関連するグループの名前は #matrixofdouble#となります.
再帰的なデータ型(list, mlist, tlist, etc)の場合, サブグループの名前が以下のように構築されます:
この # によりユニークなIDを作成できるようになります.
最初の#の数は深さのレベルを示します.
例えば, サブリスト ###listnested#_#2##_#1##は,
2番目のレベ得るに位置することを示します.
アンダースコア "_" は深さを表す手段です. 通常, "/" 文字がこのような場合に使用されますが, HDF5規約では予約済みキーワードとなっています.
名前で使用される整数は, カレントの構造における位置と親要素に関する位置の両方の意味で データ構造における位置を表します. 例えば, ###listnested#_#2##_#1##, は,親要素の3番目の構造の2番目の要素として扱われることを示します (要素は0から番号付けられます).
例えば, ###listnested#_#2##_#1##という名前のグループは, 以下の例では値 [32, 42] を指します:
疎行列
Scilab 型: sparse
HDF5 Scilab 型属性: SCILAB_Class = sparse
HDF5 属性:
SCILAB_rows = <int>
行数
SCILAB_cols = <int>
列数
SCILAB_items = <int>
疎行列における要素数を定義
ルートデータセットの値:
最初の値 (#0#):
このデータ構造の各要素は各行の非ヌル要素の数を示します.
つまり, 最初の要素は疎行列の最初の行の要素数を示します.
2番目の値 (#1#):
疎行列の各要素の列の位置を示します.
3番目の値 (#2#):
疎行列における要素の実際の値へのリファレンスを保存します
(この値は専用のグループに保存されます).
例えば, この行列を考えると:
0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 3. 0. 0. 0. 0. 2. 0. 0. 0. 0. 0.
これは以下の関数で生成されます:
sparse([1,2;4,5;3,10],[1,2,3])
これは以下となります:
#0# は,1;0;1;1を有します
#1# は,2;10;5を有します
#2# は,1.0; 3.0; 2.0を有する double(この例では複素数ではありません)の行列を参照します
論理値疎行列
Scilab型: boolean sparse
HDF5 Scilab 型属性: SCILAB_Class = boolean sparse
HDF5属性:
SCILAB_rows = <int>
行数
SCILAB_cols = <int>
列数
SCILAB_items = <int>
疎行列の要素数を定義
ルートデータセットの値: 疎行列は3つのデータセットを有しますが, 論理値疎行列は2つのみです.これは定義される値は自動的にtrueとみなされるためです.
最初の値 (#0#): このデータ構造の各要素は各行の非ゼロ要素の数を示します.
つまり, 最初の要素は疎行列の最初の行の要素数を示します.
2番目の値 (#1#):
疎行列の各要素の列の位置を示します.
以下の論理値疎行列について:
dense=[%F, %F, %T, %F, %F %T, %F, %F, %F, %F %F, %F, %F, %F, %F %F, %F, %F, %F, %T];
#0# は 1;1;0;1を有します.
#1# は 3;1;5を有します.
論理値疎行列を再生するために必要な情報は2つのみです.
HDFデータ型マッピング:
32ビット整数
Double
Scilab 型: double
HDF5 Scilab 型属性: SCILAB_Class = double
ルートデータセットの値:
実数および複素数の値は共に#<variable name>#と
呼ばれるグループに保存されます.
最初の値: 実数値へのリファレンス. 名前は#0#.
行列が複素数の場合, 2番目の値は複素数の値へのリファレンスとなります. 名前は#1#.
HDF データ型マッピング: 64-bit floating-point
多項式
Scilab 型: polynomial
HDF5 Scilab 型属性: SCILAB_Class = polynomial
HDF5 属性:
SCILAB_Class = polynomial
SCILAB_varname = <string>
シンボル変数の名前
SCILAB_Complex = <boolean>
多項式が複素数の場合 (そうでない場合は設定されません)
ルートデータセットの値:
係数はdoubleの行列の形式で(double記憶領域の関連部分に)保存されます. 係数は,複素数にできるため,複素数の行列に保存されることに注意してください. (サブ)グループとデータセットの命名規則は 本章の先頭に記述されています.
HDF データ型マッピング: Object reference
list
Scilab 型: list
HDF5 Scilab 型属性:
SCILAB_Class = list
HDF5 属性: SCILAB_items = <リストの要素数>
ルートデータセットの値:
ルートデータセットに関連して,このデータセットで保存される値は
リストに保存された値へのリファレンスです.
値は#<variable name>#と呼ばれるグループに保存されます.
この #<variable name># グループにおいて,
データは任意の型とすることができます.
これらはグループに直線的に保存されます.
その表現は他の場合と同様で,再帰的な構造にもとづきます
(種々の型のリストのリストのリストが保存および読込みできることを意味します).
(サブ)グループとデータセットの命名規則は本章の先頭に記述されています.
HDF データ型マッピング: Object reference
tlist
Scilab型: tlist
HDF5 Scilab 型属性:
SCILAB_Class = tlist
HDF5 属性: cf list
mlist
Scilab type: mlist
HDF5 Scilab 型属性:
SCILAB_Class = mlist
HDF5 attributes: cf list
void
Scilab型: void
HDF5 Scilab 型属性:
SCILAB_Class = void
void値はlist, tlistおよびmlistの非常に特殊な使用法でのみ 現れます. 以下の構文で作成することができます:
voidelement_ref=list(1,,3);
undefined
Scilab 型: undefined
HDF5 Scilab 型属性:
SCILAB_Class = undefined
undefined 値はリストの大きさが増加し, いくつかの要素が未定義となった 場合に生成されます. これらは以下の構文で生成されます:
実際の例
これらの変数全てについてサンプルファイルがScilabディストリビューションで 提供されています. これらは,以下のディレクトリで入手可能です: SCI/modules/hdf5/tests/sample_scilab_data/
本文書の編集時点で, 以下のファイルがScilabディストリビューションで提供されています:
booleanmatrix.sod
booleanscalar.sod
booleansparse.sod
emptymatrix.sod
emptysparse.sod
hypermatrixcomplex.sod
hypermatrix.sod
int16.sod
int32.sod
int8.sod
listnested.sod
list.sod
matricedoublecomplexscalar.sod
matricedoublecomplex.sod
matricedoublescalar.sod
matricedouble.sod
matricestringscalar.sod
matricestring.sod
mlist.sod
polynomialscoef.sod
polynomials.sod
sparsematrix.sod
tlist.sod
uint16.sod
uint32.sod
uint8.sod
undefinedelement.sod
voidelement.sod
フォーマットの進化
| SOD バージョン | Scilab バージョン | 説明 |
0 |
5.2.0 |
Scilab/HDF5 形式の最初のバージョン |
1 |
5.4.0 alpha / beta |
読込み/保存のデフォルト形式 前の形式 (.bin) はまだサポートされます |
2 |
5.4.0 |
double, 整数, 多項式および文字列について, 多次元 HDF5 を使用するため, SCILAB_cols / SCILAB_rows が削除されました. |
| 3 | 6.0.0 |
.bin サポートを廃止. |
参照
- save — Saves some chosen variables in a binary data file
- load — Loads some archived variables, a saved graphic figure, a library of functions
- listvarinfile — 保存されたデータファイルの中の変数の一覧を得る
- type — 変数の型を返す
- typeof — explicit type or overloading code of an object
| Report an issue | ||
| << mtell | Files : Input/Output functions | scanf >> |