Please note that the recommended version of Scilab is 2026.1.0. This page might be outdated.
See the recommended documentation of this function
h5write
データセットを作成(存在しない場合)し, データを書き込む
呼び出し手順
h5write(obj, name, data [, targetType], [, start, count [, stride [, block]]]) h5write(filename, name, data [, targetType], [, start, count [, stride [, block]]])
引数
- obj
H5Object
- name
データセットへのパスを指定する文字列
- data
Scilabデータ
- targetType
目標型を指定する文字列
- start
hyperslabのstartを保持するdouble行ベクトル
- count
hyperslabのcountを保持するdouble行ベクトル
- stride
hyperslabのstrideを保持するdouble行ベクトル
- block
hyperslabのblockを保持するdouble行ベクトル
- filename
ファイル名を指定する文字列
説明
引数として指定されたScilabデータに基づき,新たに名前付きのデータセットを作成(作成済みでない場合)します.
ターゲットのHDF5型は, HDF5マニュアルで 利用可能なリストから選択できます. この HDF5 型の例は,"H5T_MIPS_U32" または "H5T_STD_B64BE"ですが, 短縮形 "MIPS_U32" または "STD_B64BE" も使用できます.
データ上にhyperslabセレクションを作成できます.
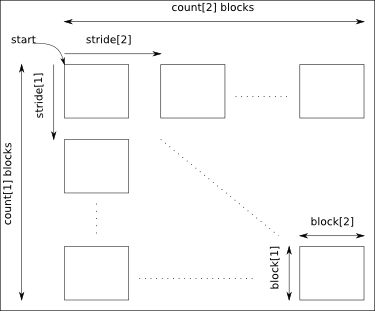
引数 start, count, stride および block はデータの次元数に等しい大きさとする必要があります:
- start: セレクションを開始するデータ内の座標を指定.
- count: 各次元で選択されたブロックの数.
- stride: 各次元において連続する2つのブロック間のシフト量を指定.
- block: ブロックの次元を指定.
目標の型が "H5T_STD_REF_OBJ"の場合,data行列は グループまたはデータセットの絶対パスを保持する文字列行列とする必要があります.
例
x = matrix(1:20, 4, 5); save(TMPDIR + "/x.sod", "x"); // SODファイルはHDF5ファイルです // 作成されたファイルをオープン a = h5open(TMPDIR + "/x.sod"); // "y"という名前の新規データセットを追加 y = uint32(matrix(10:30, 7, 3)); h5write(a, "y", y); // MIPS形式でデータセット"z"を追加 h5write(a, "z", y, "H5T_MIPS_U32"); // ここでhyperslabセレクションを作成 x = uint32(matrix(1:(11*17), 11, 17)); h5write(a, "t", x, [1 2], [2 4], [5 3], [3 2]); // 全てokかどうか確認 x, a("/t").data' // 処理を完了し, 全リソースを解放 h5close(a);
履歴
| バージョン | 記述 |
| 5.5.0 | HDF5モジュールが導入されました. |
| Report an issue | ||
| << h5umount | HDF5 Management | h5writeattr >> |