Please note that the recommended version of Scilab is 2026.1.0. This page might be outdated.
See the recommended documentation of this function
grand
乱数生成器
呼び出し手順
Y = grand(m, n, "bet", A, B) Y = grand(m, n, "bin", N, p) Y = grand(m, n, "nbn", N, p) Y = grand(m, n, "chi", Df) Y = grand(m, n, "nch", Df, Xnon) Y = grand(m, n, "exp", Av) Y = grand(m, n, "f", Dfn, Dfd) Y = grand(m, n, "nf", Dfn, Dfd, Xnon) Y = grand(m, n, "gam", shape, rate) Y = grand(m, n, "nor", Av, Sd) Y = grand(m, n, "geom", p) Y = grand(m, n, "poi", mu) Y = grand(m, n, "def") Y = grand(m, n, "unf", Low, High) Y = grand(m, n, "uin", Low, High) Y = grand(m, n, "lgi") Y = grand(m, n, o,..,"..",...) Y = grand(X, ...)
Y = grand(n, "mn", Mean, Cov) Y = grand(n, "markov", P, x0) Y = grand(n, "mul", nb, P) Y = grand(n, "prm", vect)
S = grand("getgen") grand("setgen", gen) S = grand("getsd") grand("setsd", S) grand("setcgn", G) S = grand("getcgn") S = grand("phr2sd", phrase) grand("initgn", I) grand("setall", s1, s2, s3, s4) grand("advnst", K)
パラメータ
- m, n, o
integers, size of the wanted matrix / hypermatrix
Y.- X
次元(つまり
mx n) のみ使用される行列- Y
depending on the input, a matrix or hypermatrix, with random entries.
- S
処理の出力 (通常は文字列または実数の列ベクトル)
説明
警告: シードを指定しない場合,系列はあるセッションと別のセッションで 同一のままとなります.
rand関数を使用する各スクリプトの初めに, 以下を実行する必要があります:
この関数は種々の分布により乱数を生成する際に使用することができます.
この場合,m x n行列を得るには
最初の形式が異なる3種類の呼び出し手順のどれかを適用する必要があります.
X が m x n行列の
場合,最初の2つの形式は等価で,3番目の形式は
'多値'分布(例えば,多項分布,多変量分布,ガウス分布, etc...)に対応します.
この際,サンプルは列ベクトル(つまり,次元m)で,
そのようなn個の乱数ベクトル
(つまりm x n 行列)が得られます.
最後の形式は基底生成器を変更(v2.7以降基底生成器を選択できます) したり,内部の状態(シード)を変更または取得したり,... といった基底生成器への 種々の操作を行う際に使用されます. これらの基底生成器はランダムな整数を 大きな整数区間(lgi)上の一様分布に従い, 他の全ての分布はそこから取得されます. (一般にはあるスキーム lgi -> U([0,1)) -> 指定する分布)
指定された分布から乱数を取得する
- ベータ分布
Y=grand(m,n,'bet',A,B)は パラメータAおよびdBを指定したベータ分布からランダム変量を生成します. ベータ分布の密度は (0 < x < 1) です: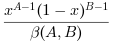
AおよびBは 実数で >10-37とします. 関係する関数は : cdfbetです.- 二項分布
Y=grand(m,n,'bin',N,p)は パラメータN(正の整数) およびp([0,1]の範囲の実数)を指定した二項分布に基づきランダム変量を生成します. この分布では,成功する確率がpのN回の独立なベルヌーイ試行における 成功回数となります. 関係する関数: binomial, cdfbin.- 負の二項分布
Y=grand(m,n,'nbn',N,p)は パラメータN(正の整数) およびp( (0,1)の実数)を指定した負の二項分布に基づきランダム変量を生成します : 成功確率pの独立なベルヌーイ試行においてN回成功する前に発生する失敗の回数. 関係する関数 : cdfnbn.- カイ二乗分布
Y=grand(m,n,'chi', Df)は,自由度Df(実数 > 0.0)を指定した カイ二乗分布に基づくランダム変量を生成します. 関係する関数: cdfchi.- 非心カイ二乗分布
Y=grand(m,n,'nch',Df,Xnon)は, 自由度Df(実数 > 0.0)および 非心度パラメータXnonc(実数 >= 0.0) を指定した非心カイ二乗分布に基づくランダム変量を生成します. 関係する関数 : cdfchn.- 指数分布
Y=grand(m,n,'exp',Av)は 平均Av(実数 >= 0.0) を指定した指数分布に基づくランダム変量を生成します.- F分布
Y=grand(m,n,'f',Dfn,Dfd)は, 分子の自由度Dfn(実数 > 0.0) および 分母の自由度Dfd(実数 > 0.0) を指定した F(分散比)分布に基づくランダム変量を生成します. 関係する関数 : cdff.- 非心F分布
Y=grand(m,n,'nf',Dfn,Dfd,Xnon)は, 分子の自由度Dfn(実数 >= 1), および 分母の自由度Dfd(実数 > 0) , および非心パラメータXnonc(実数 >= 0)を指定して 非心F分布に基づくランダム変量を生成します. 関係する関数 : cdffnc.- ガンマ分布
Y=grand(m,n,'gam',shape,rate)は,パラメータshape(実数 > 0)およびrate(実数 > 0)を指定して ガンマ分布に基づくランダム変量を生成します. ガンマの密度は以下となります :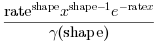
- ガウスラプラス(正規)分布
Y=grand(m,n,'nor',Av,Sd)は 平均Av(実数) および標準偏差Sd(実数 >= 0)の 正規分布に基づくランダム変量を生成します. 関係する関数 : cdfnor.- 多変量ガウス(多変量正規)分布
Y=grand(n,'mn',Mean,Cov)は,n次の多変量正規ランダム変量を 生成します;Meanはm x 1行列,Covはm x m対称正定行列です (Yはこの場合m x n行列となります).- 幾何分布
Y=grand(m,n,'geom', p)は, パラメータpを指定した 幾何分布に基づくランダム変量を生成します: (成功率pの)ベルヌーイ試行に1回成功するまでの回数.pは [1.3e-307,1]の範囲とします.Yは整数の値を有する正の実数となり, これらは "1回の成功を得る時の試行回数"です.- マルコフ分布
Y=grand(n,'markov',P,x0)は, 推移行列Pで記述されたマルコフ連鎖のn個の一連の状態量を生成します. 状態量の初期値はx0で指定されます.x0が大きさm=size(x0,'*')の 行列の場合,Yは大きさm x nの行列となります.Y(i,:)は初期状態量x0(i)から得られるサンプルパスです.- 多項分布
Y=grand(n,'mul',nb,P)は, 多項分布に基づきn個の観測量を生成します:m個のカテゴリの中にnb個の分類のイベント (m個の"boxes"の中にnb個の"balls").P(i)はあるイベントがカテゴリ i に分類される確率です. 確率ベクトルPの大きさはm-1です (カテゴリmの確率は1-sum(P)となります).Yの大きさはm x nで, 各列Y(:,j)は多項分布の観測量,Y(i,j)は(j番目の観測値に関する)カテゴリiに 分類されるイベントの数です(sum(Y(:,j)) = nb).- ポワソン分布
Y=grand(m,n,'poi',mu)は, 平均mu (実数 >= 0.0)のポワソン分布に基づき 乱数を生成します. 関係する機能 : cdfpoi.- ランダム置換
Y=grand(n,'prm',vect)は, 列ベクトル (m x 1)vectのn個の ランダム置換を生成します.- 一様分布 (def)
Y=grand(m,n,'def')は, は,[0,1)(1は含まれません) の範囲の 一様分布に基づきランダム変量を生成します.- 一様分布 (unf)
Y=grand(m,n,'unf',Low,High)は[Low, High)の範囲の一様分布に基づく の実数のランダム変量を生成します.- 一様分布 (uin)
Y=grand(m,n,'uin',Low,High)は,LowおよびHigh(含む) の範囲の一様分布に基づく の整数のランダム変量を生成します.HighおよびLowは(High-Low+1) < 2147483561の 範囲の整数とする必要があります.- 一様分布 (lgi)
Y=grand(m,n,'lgi')は カレントの生成器の基底出力として 以下の範囲の一様分布に基づくランダムな整数を返します:mt および kiss の場合は
[0, 2^32 - 1]clcg2 の場合は
[0, 2147483561]clcg4の場合は
[0, 2^31 - 2]urandの場合は
[0, 2^31 - 1].
カレントの生成器およびその状態を設定/取得
Scilab-2.7以降,異なる('lgi'分布に基づくランダムな整数,もしくは その整数に基づき得られたもの)基底生成器を選択することが 可能となっています:
- mt
周期
2^19937の M. Matsumoto および T. NishimuraのMersenne-Twister, 状態は624個の整数の配列(およびこの配列のインデックス)により 指定されます; これがデフォルトの生成器です.- kiss
周期
2^123のG. MarsagliaのKeep It Simple Stupid, 状態は4個の整数により指定されます.- clcg2
周期
2^61のP. L'Ecuyerの2線形共役合同生成器, 状態は2個の整数により指定されます; grandにより以前に(若干修正された)使用されていた生成器です.- clcg4
周期
2^121のP. L'Ecuyerの4線形合同生成器, 状態は4個の整数により指定されます; この生成器は101個の(重ならない)異なる生成器に 分割することができ,異なるタスクの場合に有用です ('clcg4に固有の動作'および 'clcg4のテスト例'を参照).- urand
scilab 関数 randで使用される生成器,
1個の整数で状態が定義され, 周期は2^31(d.e. knuth (1969), vol 2. State に示された理論と提案に基づく). これはこの一覧の中では高速ですが, やや古臭くなっています (重要なシミュレーションでは使用しないでください).
全ての生成器に共通なアクションの動作を以下に示します:
- action= 'getgen'
S=grand('getgen')はカレントの基底生成器を返します (Sは以下の文字列のどれかです: 'mt', 'kiss', 'clcg2', 'clcg4', 'urand'.- action= 'setgen'
grand('setgen',gen)は カレントの基底生成器をgenに設定します. この文字列には 'mt', 'kiss', 'clcg2', 'clcg4', 'urand' のどれかを指定します( このコールは新しいカレントの生成器を返すことに注意してください).- action= 'getsd'
S=grand('getsd')はカレントの基底生成器の カレントの状態 (カレントのシード)を返します ;Sには, mt の場合は625次 (先頭は[1,624]の範囲のインデックスです), kiss の場合は4次, clcg2の場合は2次, clcg4 の場合は4次 (最後の1つについてはカレントの仮想生成器のカレントの状態が取得されます), および urand の場合は1次 の(整数)列ベクトルが出力されます.- action= 'setsd'
grand('setsd',S), grand('setsd',s1[,s2,s3,s4])は カレントの基底生成器の状態(新しいシード)を設定します:- mtの場合
Sは625次の整数ベクトル (最初の要素はインデックスで[1,624]の範囲とする 必要があります, 続く624個の要素は[0,2^32[)の範囲とします) (しかし,全てをゼロにするすることはできません); 整数s1を1つだけ指定することで,より簡単に初期化を 行うことができます. (s1は[0,2^32[の範囲とします) ;- kissの場合
[0,2^32[の範囲の4個の整数s1,s2, s3,s4を指定します ;- clcg2の場合
2個の整数s1(範囲:[1,2147483562]) およびs2(範囲:[1,2147483398]) を指定します ;- clcg4の場合
4個の整数s1(範囲:[1,2147483646]),s2(範囲:[1,2147483542]),s3(範囲:[1,2147483422]),s4(範囲:[1,2147483322]) を指定します ;注意: clcg4の場合, カレントの仮想生成器のシードを設定しますが, この生成器と他の仮想生成器との間の同期が失われる可能性があります. すなわち,生成されるデータ列は他の生成器により生成されるデータ列と オーバーラップしていないということは保証されません) => 代わりに 'setall' オプションを使用してください.- urandの場合
[0,2^31[の範囲の1個の整数s1を指定します.
- action= 'phr2sd'
Sd=grand('phr2sd', phrase)は, 基底生成器(clcg2に適しています)の状態を変更するシードとして使用可能な1 x 2ベクトルSdを生成するphrase(文字列)を指定します.
clcg4の固有のオプション
clcg4 生成器は他の生成器と同時に使用することができますが,
系列がオーバーラップしない
複数(101個)の仮想生成器に分割できるという利点があります.
(古典的な生成器を使用する場合,異なる系列を得るために
初期状態量(シード)を別のものに変更できますが,完全に異なる系列となることは
保証されません)
各仮想生成器は2^72 個の値の系列に対応します.
これらはさらに長さW=2^41のV=2^31個の
セグメント(またはブロック)に分割されます.
指定した仮想生成器について,系列の先頭またはカレントのセグメントの先頭に戻るか
次のセグメントに直接移動するかを選択できます.
'setall'オプションにより生成器 0 の初期状態(シード)を
変更することも可能です.
これにより,同期をとるために他の仮想生成器の初期状態量を変更することも可能です.
(すなわち, gen 0 の新しい初期状態の関数として,
gen 1..100 の初期状態量は101個の
重複しない系列が得られるように再計算されます.)
- action= 'setcgn'
grand('setcgn',G)は clcg4 のカレントの仮想生成器を設定します (clcg4 が設定された時, この値は使用される仮想 (clcg4)生成器の数Gとなります); 仮想 clcg4 生成器は0,1,..,100と番号付けられます (そして,Gは[0,100]の範囲の整数となります); デフォルトで,カレントの仮想生成器は0です.- action= 'getcgn'
S=grand('getcgn')はカレントの仮想 clcg4 生成器の数を返します.- action= 'initgn'
grand('initgn',I)はカレントの仮想生成器の状態を再度初期化します- I = -1
初期シードの状態を設定します
- I = 0
直近の(前の)シードを設定します (つまり,カレントのセグメントの先頭)
- I = 1
直近のシード(すなわち,次のセグメントの先頭)から新しいシード
Wに 状態量を設定し,カレントのセグメントのパラメータをリセットします.
- action= 'setall'
grand('setall',s1,s2,s3,s4)は 生成器0の初期状態をs1,s2,s3,s4に設定します. 他の生成器の初期シードは同期がとれるように設定されます.s1, s2, s3, s4に関する制約については,'setsd'アクションを参照ください.- action= 'advnst'
grand('advnst',K)はカレントの生成器の状態を2^Kだけ前に進め,初期シードをその値でリセットします.
clcg4のテスト例
clcg4 の分割機能の適用例を以下に示します. 2つの統計上のテクニックを異なるデータの大きさで比較します. 最初の手法では,ブートストラップ手法を使用し,しらみつぶし法のみを適用する 2番目の手法よりも少ないデータで同等の精度が得られると考えられます. 最初の方法の場合,25および50の間に一様分布する大きさのデータ集合が生成されます. その後,指定した大きさのデータ集合が生成され,解析されます. 2番目の方法は, 100および200の間の大きさのデータ集合を選択し,データを生成し,解析します. この過程を1000回繰り返します. 分散を減少させるために,2つの手法で使用される乱数を1000回の比較の各回で 同じとすることが望まれます. しかし,2番目の手法は1番目の手法よりも多くの乱数を使用し, このパッケージなしでは同期は困難となります. clcg4 ではこれは容易です. 生成器 0 を使用し最初の手法のサンプルの大きさを取得し, 生成器 1 をデータを得る際に使用します. 次にカレントのブロックの先頭に状態をリセットし, 2番目の手法にも同様のことをします. これにより,2番目の手法で使用される初期データが1番目の手法で使用されることが 保証されます. 両方の処理が完了した時,両方の生成器のブロックを前に進めます.
参照
- rand — 乱数生成
- sprand — ランダム疎行列
- ssrand — 乱数生成器
- randpencil — ランダムなペンシル
- genmarkov — 再帰的および一時的なクラスを有するランダムなマルコフ行列を生成する
| Report an issue | ||
| << random | random | noisegen >> |